

This article builds upon my previous two articles where I share some tips on how to get started with data analysis in Python (or R) and explain some basic concepts on text analysis in Python. In this article, I want to go a step further and talk about how to get started with text classification with the help of machine learning.
The motivation behind writing this article is the same as the previous ones: because there are enough people out there who are stuck with tools that are not optimal for the given task, e.g. using MS Excel for text analysis. I want to encourage people to use Python, not be scared of programming, and automate as much of their work as possible.
Speaking of automation, in my last article I presented some methods on how to extract information out of textual data, using railroad incident reports as an example. Instead of having to read each incident text, I showed how to extract the most common words from a dataset (to get an overall idea of the data), how to look for specific words like “damage” or “hazardous materials” in order to log whether damages occurred or not, and how to extract the cost of the damages with the help of regular expressions.
However, what if there are too many words to look for? Using crime reports as an example — what if you are interested in whether minors were involved? There are many different words you can use to describe minors: Underaged person, minor, youth, teenager, juvenile, adolescent, etc. Keeping track of all these words would be rather tedious. But, if you have already labeled data from the past, there is a simple solution. Assuming you have a dataset of previous crime reports that you have labeled manually, you can train a classifier that can learn the patterns of the labeled crime reports and match them to the labels (whether a minor was involved, whether the person was intoxicated, etc). If you get a new batch of unlabelled crime reports, you could run the classifier on the new data and label the reports automatically, without ever having to read them. Sounds great, doesn’t it? And what if I told you that this can be done in as little as 7 lines of code? Mind blowing, I know.
In this article, I will go over some main concepts in machine learning and natural language processing (NLP) and link articles for further reading. Some knowledge of text preprocessing is required, like stopword removal and lemmatisation, which I described in my previous article. I will then show on a real-world example, using a dataset that I have acquired during my latest PhD study, how to train a classifier.
Classification Problem
Classification is the task of identifying to which of a set of categories a new observation belongs. An easy example would be the classification of emails into spam and ham (binary classification). If you have more than two categories it’s called multi-class classification. There are several popular classification algorithms which I will not discuss in depth but invite you to check out the provided links and do your own research:
- Logistic regression (check out this video and this article for a great explanation)
- K-nearest neighbour (KNN) (video, article)
- Support-vector machines (SVM) (video, article)
- Naive Bayes (video, article)
- Decision Trees (video, article)
- Neural Networks (video, article)
Training and Testing Data
When you receive a new email, the email is not labelled as “spam” or “ham” by the sender. Your email provider has to label the incoming email as either ham and send it to your inbox, or spam and send it into the spam folder. To tell how well your classifier (machine learning model) works in the real world, you split your data into a training and a testing set during the development.
Let’s say you have 1000 emails that are labelled as spam and ham. If you train your classifier with the whole data you have no data left to tell how accurate your classifier is. This is because you do not have any e-mail examples that the model has not seen. So you want to leave some emails out of the training set. Let your trained model predict the labels of those left-out emails (testing set). By comparing the predicted with the actual labels you will be able to tell how well your model generalises to new data, and how it would perform in the real world.
Representing text in computer-readable format (numbers)
Ok, so now you have your data, you have divided it into a training and a testing set, let’s start training the classifier, no? Given, that we are dealing with text data, there is one more thing we need to do. If we were dealing with numerical data, we could feed those numbers into the classifier directly. But computers don’t understand text. The text has to be converted into numbers, known as text vectorisation. There are several ways of doing it, but I will only go through one. Check out these articles for further reading on tf-idf and word embeddings.
A popular and simple method of feature extraction with text data is called the bag-of
-words model of text. Let’s take the following sentence as an example:
“apples are great but so are pears, however, sometimes I feel like oranges and on other days I like bananas”
This quote is used as our vocabulary. The sentence contains 17 distinct words. The following three sentences can then be represented as vectors using our vocabulary:
“I like apples”
“Bananas are great. Bananas are awesome,”
[0, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2]
or
[0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1] if you don’t care how often a word occurs.
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Below you can see a representation of the sentence vectors in table format.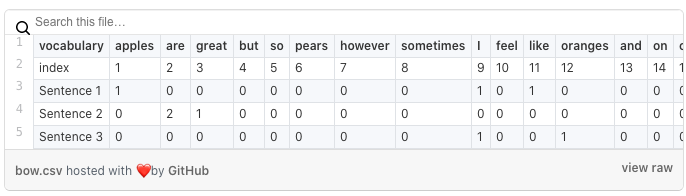
You can see that we count how often each word of the vocabulary shows up in the vector representation of the sentence. Words that are not in our initial vocabulary are of course not known. Therefore the last sentence contains only zeros. You should now be able to see how a classifier can identify patterns when trying to predict the label of a sentence. Imagine a training set that contains sentences about different fruits. The sentences that talk about apples will have a value of higher than 0 at index 1 in the vector representation. Whereas sentences that talk about bananas will have a value of higher than 0 at index 17 in the vector representation.
Measuring accuracy
Great, now we have trained our classifier, how do we know how accurate it is? That depends on your type of data. The simplest way to measure the accuracy of your classifier is by comparing the predictions on the test set with the actual labels. If the classifier got 80/100 correct, the accuracy is 80%. There are, however, a few things to consider. I will not go into great detail but will give an example to demonstrate my point. Imagine you have a dataset about credit fraud. This dataset contains transactions made by credit cards and presents transactions that occurred in two days. Tere were 492 frauds out of 284,807 transactions. You can see that the dataset is highly unbalanced and frauds account for only 0.172% of all transactions. You could assign “not fraud” to all transactions and get 99.98% accuracy”! This sounds great but completely misses the point of detecting fraud as we have identified exactly 0% of the fraud cases.
Here is an article that explains different ways to evaluate machine learning models. And here another one that describes techniques of how to deal with unbalanced data.
Cross-Validation
There is one more concept I want to introduce before going through a coding example, which is cross-validation. There are many great videos and articles that explain cross-validation so, again, I will only quickly touch upon it in regards of accuracy evaluation. Cross-validation is usually used to avoid over- and underfitting of the model on the training data. This is an important concept in machine learning, so I invite you to read up on it.
When splitting your data into training and testing set. What if you got lucky with the testing set and the performance of the model on it overestimates? How well your model would perform in real life? Or the opposite. What if you got unlucky and your model might perform better on real-world data than on the testing set. To get a more general idea of your model’s accuracy, it makes sense to perform several different training . Testing splits and averaging the different accuracies that you get for each iteration.
Classifying people’s concerns about a potential COVID-19 vaccine.
Initially, I wanted to use a public dataset from the BBC comprised of 2225 articles. Each labeled under one of 5 categories: business, entertainment, politics, sport or tech, and train a classifier that can predict the category of a news article. However, often popular datasets give you very high accuracy scores without having to do much preprocessing of the data. The notebook is available here. Here I demonstrate that you can get 97% accuracy without doing anything with the textual data. This is great but, unfortunately, not how it works for most problems in real life.
So, I used my own small dataset instead, which I collected during my latest PhD study. Once I have finished writing the paper I will link it here. I have crowdsourced arguments from people who are opposed to taking a COVID-19 vaccine should one be developed. I labeled the data partially automatically, partially manually by “concern” that the argument addresses. The most popular concern is, not surprisingly, potential side effects of the vaccine, followed by a lack of trust in the government. As well as concerns about insufficient testing due to the speed of the vaccine’s development.
Scikit-learn
I am using Python and the scikit-learn library for this task. Scikit-learn can do a lot of the heavy lifting for you. Which,as stated in the title of this article, allows you to code up classifiers for textual data in as little as 7 lines of code. So, let’s start!
After reading in the data, which is a CSV file that contains 2 columns, the argument, and it’s assigned concern, I am first preprocessing the data. I describe preprocessing methods in my last article. I add a new column that contains the preprocessed arguments into the data frame. Iwill use the preprocessed arguments to train the classifier(s).
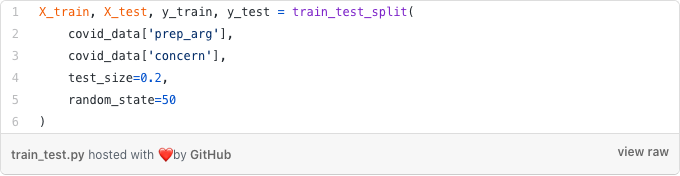
I classify the arguments and their labels into training and testing set at an 80:20 ratio. Scikit-learn has a train_test_split function which can also stratify and shuffle the data for you.

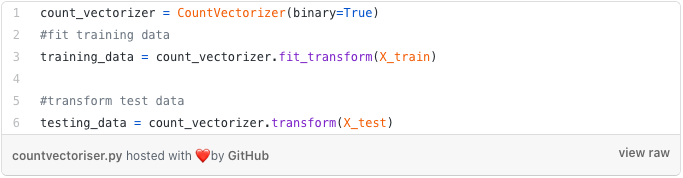
Next, I instantiate a CountVectoriser to transform the arguments into sparse vectors, as described above. Then I call the fit() function to learn the vocabulary from the arguments in the testing set. Afterward, I call the transform() function on the arguments to encode each as a vector (scikit-learn provides a function which does both steps at the same time). Now note, that I only call transform() on the testing arguments. Why? Because I do not want to learn the vocabulary from the testing arguments and introduce bias into the classifier.
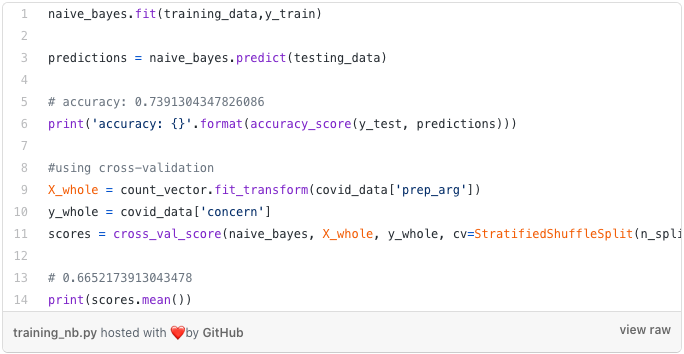
Finally, I instantiate a multinomial Naive Bayes, fit it on the training arguments, test it on the testing arguments, and print out the accuracy score. Almost 74%. But what if we use cross-validation? Then accuracy drops to 67%. So we were just lucky with the testing data that the random state created. The random state ensures that the splits that you generate are reproducible.
Out of curiosity, I am printing out the predictions in the notebook and check what arguments the classifier got wrong. We can see that mostly the concern “side_effects” is assigned to wrongly labelled arguments. This makes sense because the dataset is unbalanced. There are more than twice as many arguments that address side effects than for the second most popular concern, lack of government trust. So assigning side effects as a concern has a higher chance of being correct than assigning another one. I have tried undersampling and dropped some side effects arguments but the results were not great. You should experiment with it.
I coded up a few more classifiers, and we can see that accuracy for all of them is around 70% and managed to get it up to 74% using a support vector machine and dropping around 30 side_effect arguments. I have also coded up a neutral network using tensorflow, which is beyond the scope of this article, which increased accuracy by almost 10%.
This article I hope will provide you with the necessary resources to get started with machine learning on textual data. Feel free to use any of the code from the notebook. I encourage you to play around with different preprocessing methods, classification algorithms, text vectorisations and, of course, datasets.







