When you take your first steps into machine learning, the first concept you will come across is probably regression or regression analysis. What is regression analysis, though?
In statistics, regression is a technique used to examine the relationship between one dependent variable and one or more independent variables. The main goal is to model this relationship so that we can make predictions or understand the underlying patterns of the data.
There are various types of regression analysis used in statistics today. The best two to start with are linear and logistic regression. Both of these regressions provide a straightforward model to understand the relation between two sides of an equation (or two sets of variables). The difference between them is that linear regression can only model linear relationships between the variables, while logistic regression can model non-linear ones, much like the diverse functionalities detailed in A brief overview of how Git works.
In this article, we will explore the basics of linear and logistic regression using Python and Scikit-learn. So, let’s get right to it!
What is Linear regression?
Linear regression is a fundamental statistical method used to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
Linear regression is used in different areas of our lives, such as:
Since linear regression is the simplest form of regression analysis, it is easy to write an implementation for it in Python. Let’s start with a simple linear regression example where we have one dependent variable and one independent variable in 7 steps:
In code, this would look something like:

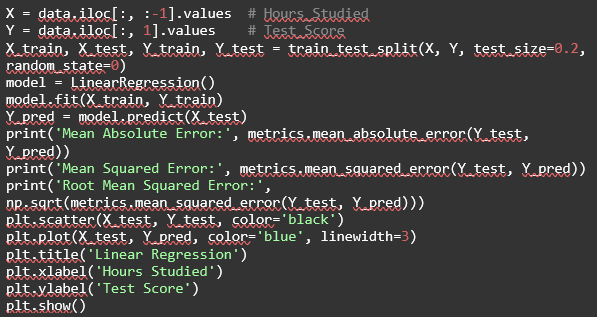
For this example, let’s consider a hypothetical dataset stored in a file named data.csv with two columns: Hours_Studied and Test_Score.

Then, we need to split the data into the independent variable X and the dependent variable Y.
Logistic Regression
Linear regression can only predict a linear relationship between the variables, which is not always the case. That’s why we need different types of regression to allow us to explore these different scenarios. One such regression is logistic regression. Logistic regression is another type of regression analysis used when the dependent variable is categorical, typically used for binary classification problems, i.e., when the outcome can be one of two classes. For example, it can be used to predict whether an email is spam or not spam or whether a tumor is malignant or benign.
The logistic regression model predicts the probability that a given instance belongs to a particular category or not based on a threshold value. If the estimated chance is greater than a threshold (often set to 0.5), then the model predicts that the instance belongs to that category; otherwise, it will indicate it does not.
Though logistic regression is slightly more complex than linear regression, its implementation in Python is just as simple, thanks to Scikit-learn!
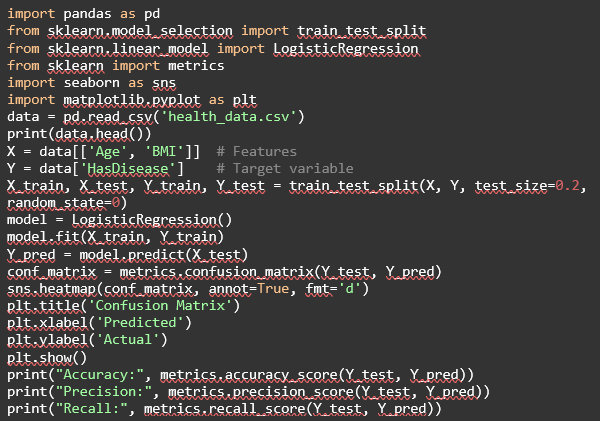
Let’s go through an example of logistic regression using Python. Suppose we have a dataset stored in a file called health_data.csv with two columns, “Age” and “BMI”,” and we want to predict the binary outcome “HasDisease”.”
We can do that by following the same steps we did for linear regression. If we write it down as code, it would look like this:
Conclusion
Regression analysis is one of the powerful statistical methods that allows you to uncover the relationship between two or more variables. These variables are often referred to as the dependent and the independent variables. In statistics and machine learning, there are many types of regression analysis; each has its optimal case use. Perhaps the simplest and most commonly used ones are linear and logistic regression. You can implement these two regressions (and more) using Python with libraries such as scikit-learn.
This article briefly introduced linear and logistic regressions and their implementation using Python. However, real-world scenarios often involve multiple independent variables and may require more complex models like multiple linear regression, polynomial regression, or other advanced regression techniques. Nevertheless, the approaches to all different regression algorithms are the same, and it all depends on your desired output and the type of data you have. So, as a beginner, you will need to explore and experiment with different models and datasets to deepen your understanding of regression analysis until you know what regression model to use for specific applications and the required results.