

This blog post is a gentle introduction to Natural Language Processing (NLP).
After reading this, you will know some basic techniques to extract features from text which can be used as input for machine learning models, and what word embeddings are.
What is NLP?
NLP is a branch of artificial intelligence that deals with analysing, understanding, and generating human (natural) languages. You use applications that utilise NLP on a daily basis, for example, when using Google Translate to translate a piece of text, your email service which uses NLP to detect spam, autocomplete and grammar check on your phone, and many more.
Getting started
Given a piece of text, we need to transform it into computer-readable format – vectors. In this article, we will cover different ways to do that, as well as different preprocessing techniques.
1. Tokenisation
Tokenisation is the process of breaking up text into individual words called tokens. Although this might sound simple, this problem is not trivial. In languages like English, space is a good approximation of a word divider. However, we run into problems if we only split by space.

If we only split by space, the last word of each sentence would include a punctuation sign, which we don’t want. But singling out punctuation as a separate token is not always correct, for example in the word “Mr.”.
In English this problem is simple enough to come up with a set of rules that can be hard-coded to achieve good results. But what about languages that do not use space, like Japanese? Or if the text is very domain-specific, as shown in the example below? In this case, we need to use machine learning to train a tokeniser.

Unless you deal with a very specific domain that requires a domain-specific tokeniser, there is no need for you to code up a tokeniser. Luckily, all NLP libraries come with a suite of text processing functions, including one for tokenisation. One such library for Python is the Natural Language Toolkit (NLTK) which contains the nltk.word_tokenize function.
2. Preprocessing
Depending on the task, you might want to preprocess the text instead of using whole sentences. A spam detector, for example, relies on certain features that are present in the data.
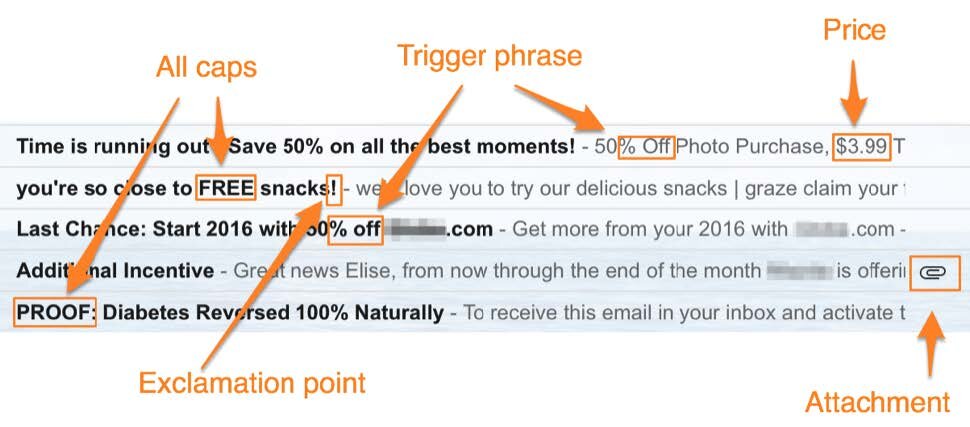
Common ways to preprocess your text include lemmatising and stemming, stopword removal, and normalisation. Check out this notebook for some examples.
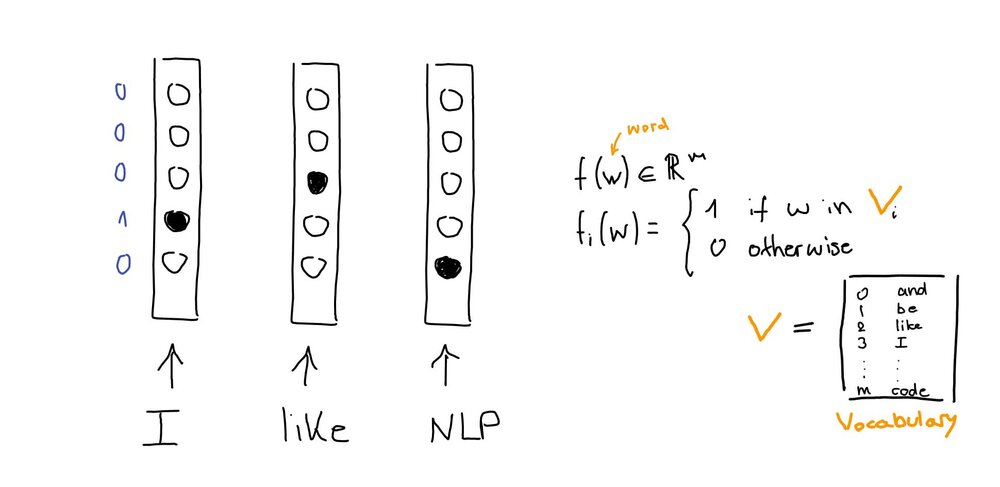
3. Representing Words with One-Hot Vectors
Ok, now that we have tokenised and preprocessed our text, it is time to convert it into computer-readable vectors. This is called feature extraction. The bag-of-words (BOW) model is a popular and simple feature extraction technique. The intuition behind BOW is that two sentences are said to be similar if they contain a similar set of words. BOW constructs a dictionary of m unique words in the corpus (vocabulary) and converts each word into a sparse vector of size m, where all values are set to 0 apart from the index of that word in the vocabulary.
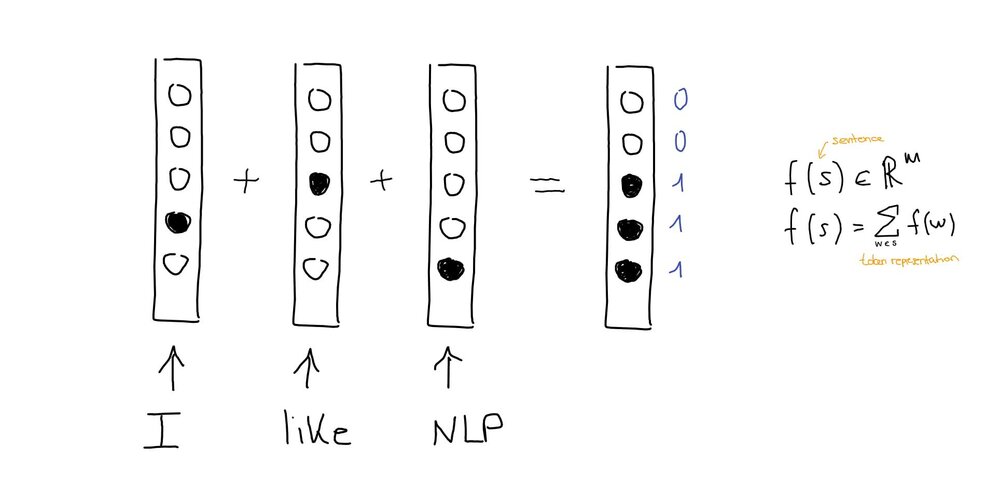
A sentence can be represented by adding the vectors together. There are different ways of doing that: max-pooling only counts whether a word is present, but not how many times. Sum pooling counts the number of occurrences of each word (the one-hot vector for “I like, like, NLP” using max-pooling would be the same as for “I like NLP”, whereas sum pooling would produce in the vector [0,0,2,1,1] ).
Like for tokenisation, there is no need to code this up from scratch – text vectorisation functions are available in all popular machine learning libraries, e.g. CountVectorizer from scikit-learn.
Word Embeddings
Now you know how to convert text into vectors. These vectors can be used to train models for classification tasks, for example, spam detection or sentiment analysis. Linear classification models will be covered in the next blog post. BOW works quite well for certain tasks and is very simple to understand and implement. However, BOW has several disadvantages. Firstly, it produces very large but sparse feature vectors. And secondly, it assumes all words are independent of each other.
Let’s demonstrate that problem with an example. Let’s assume we want to classify news articles by topic (sports, politics, etc.).
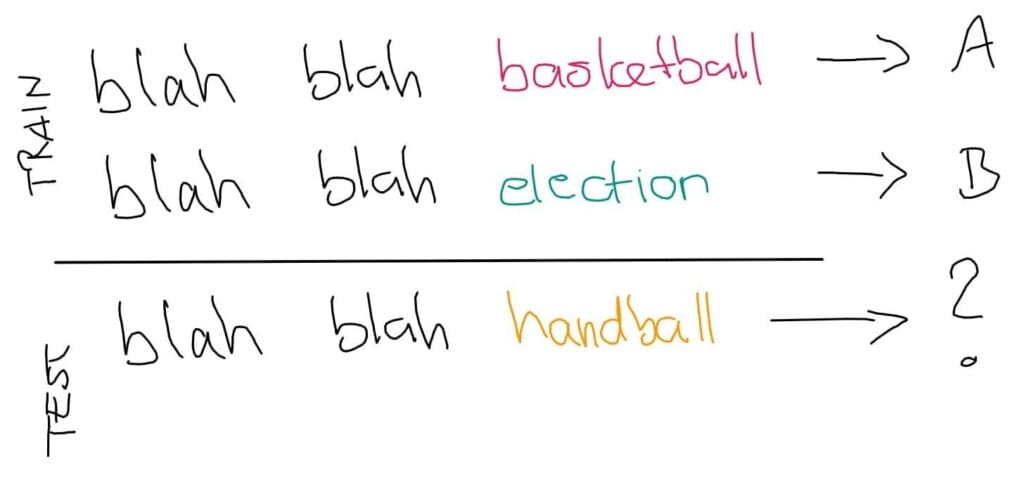
We can easily see that the test sentence should be labeled as A (sports) because handball is a sport. But the computer does not know that. The computer only sees symbols that are either contained in the vocabulary or not.
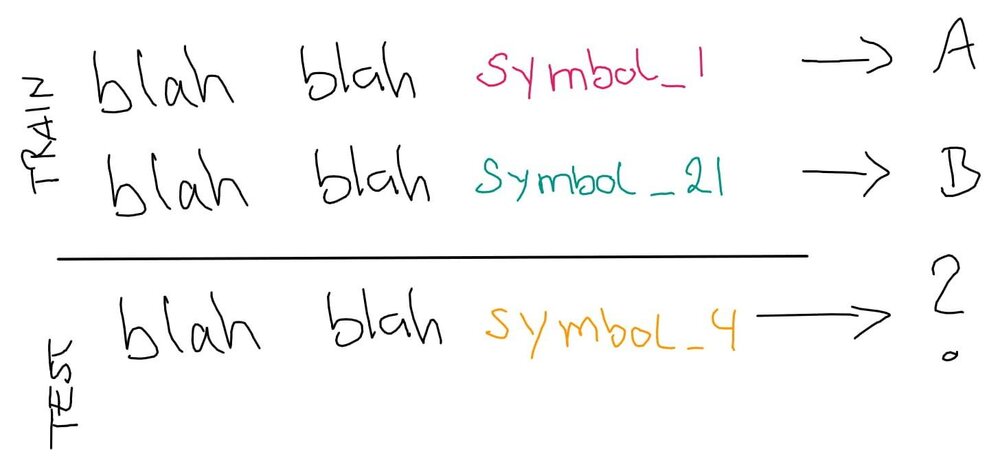
A computer cannot generalise like we can based one some prior knowledge that we have about the domain. This is a fundamental issue when using BOW to represent sentences – one-hot encoded vectors cannot capture similarities of words.
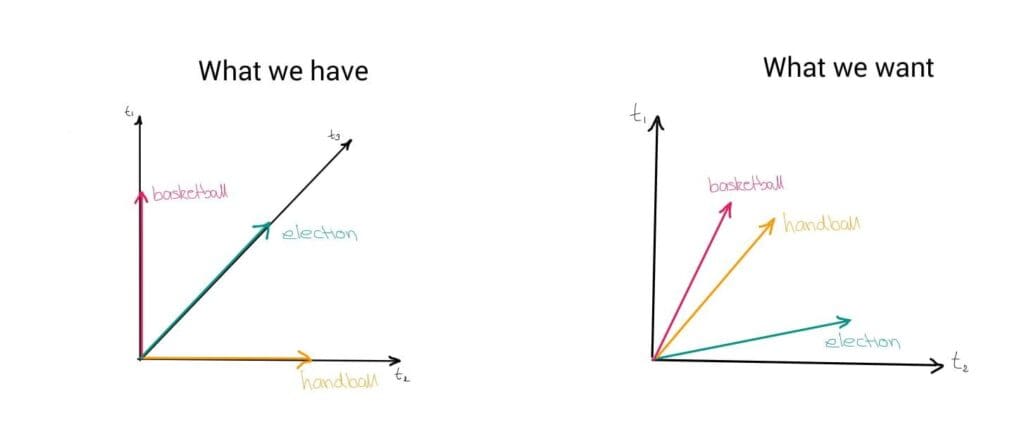
The solution are distributed representations that introduce some dependence of one word on the other words. This way, words that are more similar to each other will be placed closer to each other in the embedding space. Now we can calculate how similar words are by measuring the distance between them.
This post won’t describe how algorithms that create word embeddings work, but if you are interested to find out more about it, check out this blog post. Instead, I want to give a high-level example on how word embeddings look.
Imagine a small vocabulary containing 5 words: king, queen, man, woman, and princess. The one-hot vector for queen would look like this:
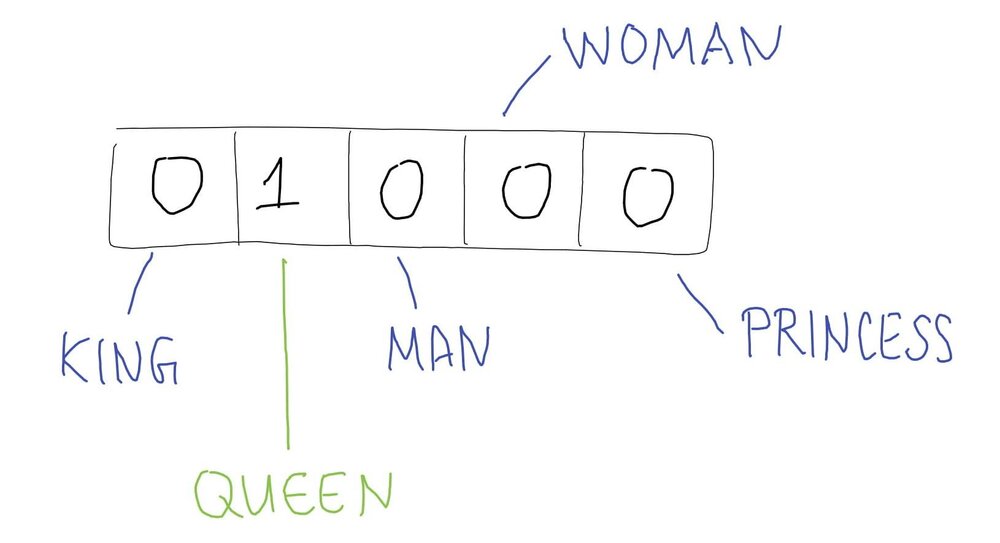
But we know that words are rich entities with many layers of connotation and meaning. Let’s hand-craft some semantic features for these 5 words. We will represent each word as having some value between 0 and 1 for 5 semantic qualities: royalty, masculinity, femininity, age, and edibility.
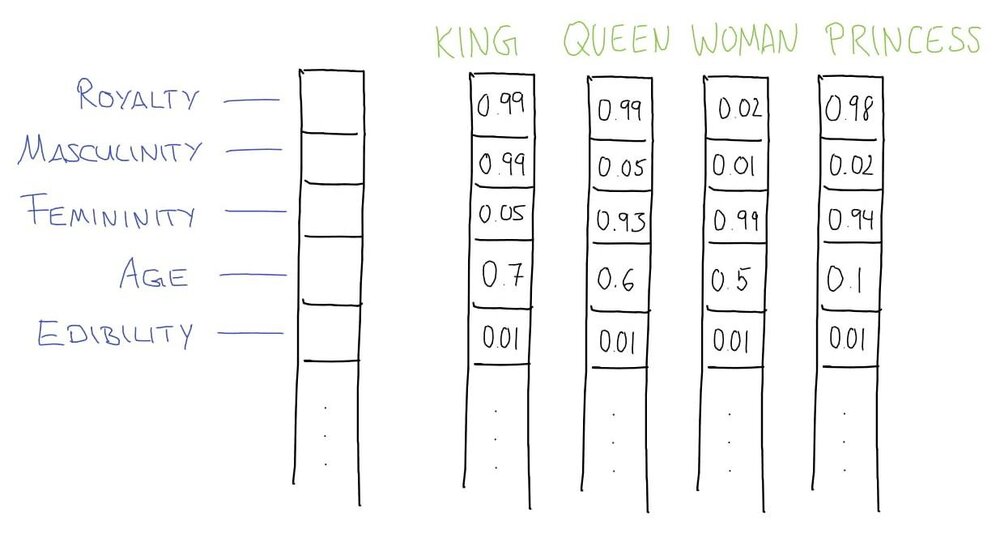
Given the word “king”, it has a high value for the feature “royalty” (because a king is a male member of the royal family) but a low value for femininity (because he is male) and an even lower value for edibility (because we do not normally eat kings). In the above made-up toy dataset, there are 5 semantic features, and we can plot three of these at a time as a 3D scatter plot with each feature being an axis/dimension.
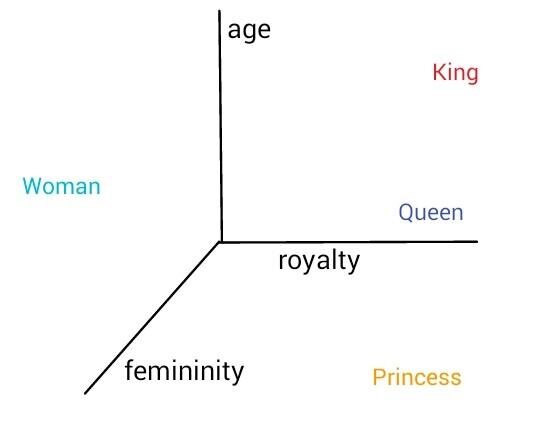
You do not have to create word embeddings yourself. Pre-trained word embeddings can be downloaded and used in your models.
I hope you found this blog post useful and have learnt some basic NLP tasks, how one-hot encoding works and what word embeddings are.

AUTHOR:
Lisa A Chalaguine
SheCanCode Blog Squad







