

In my two previous articles, I quickly introduced word embeddings created using neural networks but mainly focused on traditional machine-learning models that utilize one-hot encoded vectors as input. However, these vectors are a naïve representation of text, and a Deep Dive into Language Learning Models ‘LLM’ is necessary to grasp the complexities of human language and its non-linear nature.
This is where neural networks come in. And not just any neural network but networks that can deal with sequential data (or in general data that follows certain patterns, not necessarily sequential, but more on that in a bit).
Even if you don’t know exactly how a neural network works (explaining that is out of the scope of this article), I assume you have seen an image like this before:
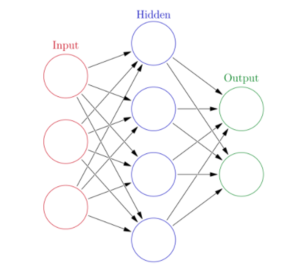
As you can see there is only one input layer, so the input data would be one-dimensional for this simple feed-forward neural network. One could concatenate the word embeddings for each word in a sentence, however this produces input embeddings of different lengths.
This is problematic given we have a fixed input size. Also, imagine you want to create a paragraph or even a document embedding – this would create huge vectors. Another way would be to average the word embeddings of individual words to get a sentence/paragraph/document embedding.
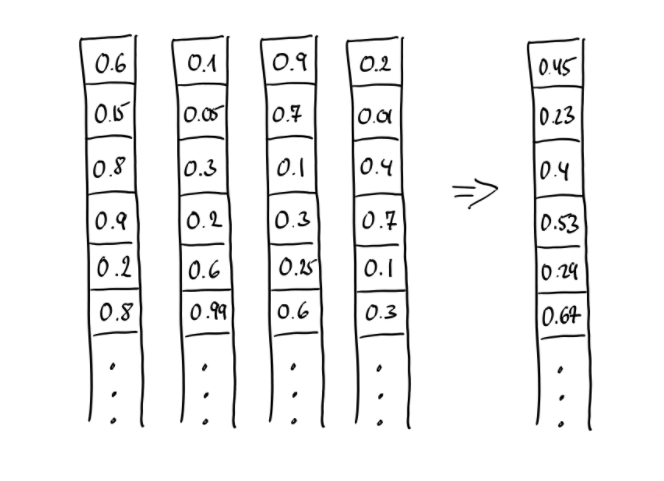
However, when vectors are linearly combined by addition/subtraction/multiplication (either followed by averaging or not) the resulting vector cannot be uniquely decomposed into its original components, which means that all the information about the individual vectors are lost, since a vector of real values can be decomposed into components in an infinite number of ways. If you look at the first number in each vector in the picture above – (0.6 + 0.1 + 0.9 + 0.2) / 4 = 0.45. But 0.3 + 0.7 + 0.2 + 0.6 when averaged would give the same result. Hence, a quite different piece of text might result in a similar document embedding.
So simple feed-forward neural network architectures won’t get us very far. This is where convolutional neural networks (CNNs), recurrent neural networks (RNNs), long-short term memory neural networks (LSTMs), sequence-2-sequence models and transformers come in.
Convolutional neural networks (CNNs)
Let’s start with an easy example that does not even involve word embeddings in order to demonstrate the use of CNNs. CNNs have the ability to detect complex features in data, for example, extracting features from images and text. They have mainly been used in computer vision (e.g. for image classification, object detection and image segmentation), however, they have also been applied to problems involving textual data.
A CNN is made up of two main layers: a convolutional layer for obtaining features from the data, and a pooling layer for reducing the size of the feature map. In short, convolution is the process through which features are obtained with the help of a feature detector (also called kernel or filter). This can be, for example, a 3 x 3 matrix which slides over your input matrix (an image) and performs element-wise multiplication of the kernel and the input matrix.
In order to capture different patterns, you could have several 3 x 3 matrices sliding over your input matrix. Further, each point in the input can have several dimensions. These are called channels. For example, in images there are three channels for each pixel in the image, corresponding to the RGB components. Using the same analogy for textual data, the “pixels” in a text are words.
So the number of initial input channels is the size of the vocabulary (for one-hot encoded vectors) or the dimension size (for word embeddings). In the example below you see two different kernels sliding over a piece of text and their convolved output.
As an example to demonstrate the usefulness of CNNs we will use last name classification. Last names cannot be embedded for obvious reasons, so one-hot encoding of the letters (and symbols) is the appropriate method to create the vector representations. Using a linear approach or a simple feed-forward neural network, will not be able to find segments that reveal the origin of the last name (such as the “O’” in Irish last names like “O’Brien”, the ending “ov” for Russian, and the ending “ko” for Ukrainian).
These segments can be of variable lengths, and the challenge is to capture them without encoding them explicitly. CNNs are well suited for that because, as described in the previous paragraph, they can detect spatial substructure. However, they cannot capture sequential data, which leads us to our next topic.
Recurrent neural networkS + long-short term memory neural networks
Traditional machine learning assumes that data points are independently and identically distributed (IID). However, often one data item depends on the item that precedes or follows it, such as in language. Language is sequential. CNNs and simple neural networks as shown above cannot model sequences. Modelling sequences involves maintaining a hidden state. This hidden state captures previous information and gets updated with each new data piece (e.g. new word in the sentence seen by the model).
The most basic neural network sequence model is the recurrent neural network (RNN). And the most basic RNN has only one hidden state and hence only one hidden cell. You will come across this terminology when reading about RNNs – it creates some confusion amongst people. The name does not refer to a single cell but rather a whole layer. However, the RNN is feeding to itself (output of previous time step becomes the input of the current time step) and thus the RNN layer comprises a single rolled RNN cell that unrolls according to the number of time steps/segments/words you provide.
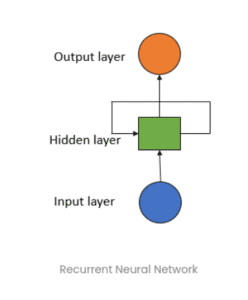 Thanks to the hidden state RNNs have the ability to capture short-term dependencies. It retains information from one time step to another flowing through the unrolled RNN units. The current time step’s hidden state is calculated using information of the previous time step’s hidden state and the current input. However, the problem with RNNs is that long-term information has to sequential travel through all cells before getting to the present processing cell.
Thanks to the hidden state RNNs have the ability to capture short-term dependencies. It retains information from one time step to another flowing through the unrolled RNN units. The current time step’s hidden state is calculated using information of the previous time step’s hidden state and the current input. However, the problem with RNNs is that long-term information has to sequential travel through all cells before getting to the present processing cell.
Think about it: an unrolled RNN is very (very!) deep – as deep as N with N timesteps. But the weight matrix for each time step is the same given that the unrolled network is composed of duplicates of the same network. So during backpropagation, when calculating the gradient of a specific weight is very large or very small the gradient gets multiplied by this very small or very large value over and over again which results in either vanishing or exploding gradients.
To the rescue came the LSTM module. An LSTM is basically a fancy RNN. They have an additional “memory cell” which has the ability to remove or add information to the memory, regulated by “gates”. However, despite partially solving the exploding and vanishing gradient problem, we still have a sequential path from older cells to the current one.
Although they are able to learn a lot of longer term information, they cannot remember sequences of 1000s or 10000s of words. Both RNNs and LSTMs are also not very hardware friendly and take a long time to train.
Seq2seq models
In the last name classification example above the input to the model was a sequence of characters and the output was a single class (e.g. “Scottish”). But what about tasks like machine translation where the input and the output are sequences? Sequence-to-sequence learning (seq2seq) is about training models to convert sequences from one domain to sequences in another domain.
The main challenge in such tasks is the fact that the input and output sequences are of different and varying lengths for each training example and that the entire input sequence is required in order to predict the target. Hence, a more advanced setup is needed.
Without going into too much technical details, this is how it works:
An RNN or LSTM layer (or stack of them) acts as an “encoder”: they process the input sequence and output the final hidden state vector which aims to encapsulate the information for all input elements in order to help the decoder make accurate predictions. This vector acts as the initial hidden state of the decoder part of the model. Another RNN or LSTM layer (or stack) acts as a “decoder”: they are trained to predict the next words of the target sequence, given previous words of the target sequence.
The decoder uses the final hidden state vector from the encoder in order to obtain information about what it is supposed to generate. In order to prevent the decoder from propagating a wrong prediction into future predictions, the correct word from the target sequence is fed into the decoder once the prediction is made (hence off-set by one time step) – a process called “teacher forcing”. Effectively, the decoder learns to sequentially generate targets[t+1] given target[t], conditioned on the initial hidden state vector it received from the encoder.
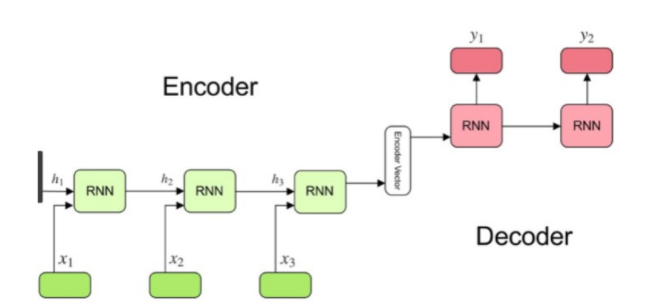
You might already see a clear drawback of this architecture: using a single vector for encoding the whole input sequence is not capable of capturing the whole information. So the challenge of dealing with long-range dependencies between words that are far apart in a long sentence remains. Another limitation is the long training and inference time of such models due to the sequential calculations.
There are several ways to address the first problem like reversing the sentence that is being fed into the encoder because it shortens the path from the decoder to the relevant parts of the encoder, or feeding in the input sentence twice. These approaches, however, do not generalise well to all languages. Most benchmarks are set for languages like English, German and French, which all have quite similar word order (they are SVO languages – Subject, Verb, Object).
Languages like Japanese and Korean, however, are SOV. Hence, the last word in a sentence of an SOV language, might be the second one in an SVO language. In such a case, reversing the input would make things worse.
Attention and Transformers
So what is the alternative to the approaches named above to deal with long-term dependencies? The answer is – attention. Attention is one of the most powerful concepts in the field of deep learning these days. It is based on the intuition that we “attend to” a certain part when processing large amounts of information. The concept was first introduced by Bahdanau et al (2015) who proposed utilising a context vector to align the source and target inputs.
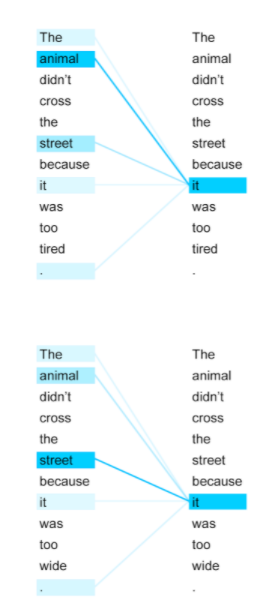
Rather than building a single context vector out of the encoder’s last hidden state, the context vector preserves information from all hidden states from the encoder cells and aligns them with the current target output. By doing so, the decoder is able to attend to a certain part of the source inputs and learn the complex relationship between the source and the target better.
In languages that are pretty well aligned (e.g. German and English), the decoder would probably choose to attend to things more or less sequentially (see picture below where attention is sequentially until “European Economic Area” which is “zone économique européenne” in French). However, because the context vector has access to the entire input sequence, we don’t need to worry about forgetting long-term dependencies.

So with the long-term dependency problem out of the way, how do we solve the problem of long training times due to the sequential nature of the encoder-decoder architecture described above? You probably came across the term “transformer” before, when reading about NLP.
The transformer is an architecture that aims to solve sequence-to-sequence tasks which handle long-range dependencies using attention. It was first introduced in the paper Attention is all you need, and since then several projects including BERT (Google) and GPT (OpenAI) have built on this foundation.
Without going into too many details, transformers contain a stack of identical Encoder layers and a stack of identical Decoder layers. The transformer’s architecture does not contain any recurrence or convolution thanks to self-attention and positional encoding which ditches all sequential operations in favour of parallel computation. Compared to the attention described above, self-attention aligns words in a sequence with other words in the sequence, thereby calculating a representation of the sequence.
Final words
 Self attention. Source: googleblog
Self attention. Source: googleblog
We only scratched the surface in this article about all the different break-throughs in natural language processing and deep learning in general, but I hope I managed to give you an overview about the more “traditional” neural models and how new architectures like the transformer addressed their drawbacks.
There are many resources out there that will help you to get started with neural models for NLP. Some of my favourite books and tutorials are listed below.
Books:
– Natural Language Processing with PyTorch
– Getting started with Deep Learning for Natural Language Processing: Learn how to build NLP applications with Deep Learning – Deep Learning for NLP and Speech Recognition
Blogs:
– Understanding Transformers
– Overview of Transformers (4 parts)







{kind=link}