
We live in an era where artificial intelligence (AI) can no longer afford to be a black box. Developers of AI models are expected to explain the AI decisions to end users and stakeholders, and a Deep Dive into Language Learning Models ‘LLM’ is essential to ensure models perform as expected and can be effectively communicated.
WHY EXPLAINABILITY?
Suppose as a data scientist you are building a model which predicts customers who are at high risk of loan default with a view of rejecting the customer from acquiring the loan if the probability is very high. A customer who has been rejected by the model can demand to know why he was rejected.
Sometimes it’s the middlemen who would argue with the sales team and seek answers as to why their customer was rejected. And as per the “right to explanation” of the Data Protection Act 2018 General Data Protection Regulation any company implementing automated decision-making is bound to oblige. Regulators like FCA can demand to know if there is any discrimination being done (based on race, gender, ethnicity, or any hidden bias) by the company because of the machine learning model being used.
Business stakeholders hold you responsible for the model results and would like to know what variables are affecting the model as a whole and as and when a query comes from the end customer. The operations team should also have the transparency for them to use the model with confidence and this helps in change management and fosters adoption of the model. The compliance team keeps an eye on model variables and results to make sure there is no bias. And last but not least, data scientists themselves need to fully understand and comprehend the model results because the model might be inherently making wrong decisions.
INTUITIONS BEHIND LIME:
LIME is one of the popularly used algorithms and stands for Local Interpretable Model Agnostics Explanations. The word “local” means LIME and is used to explain each record separately rather than the whole dataset; “Interpretable” refers to the fact that it is easily interpretable by everyone. “Model Agnostic” because it can be used to explain any black box model.
LIME is about building a surrogate model also known as local approximation around the data point, we want to explain. Instead of focusing on the whole complex model, we zoom in and build a simple model around the instance that we want to explain.
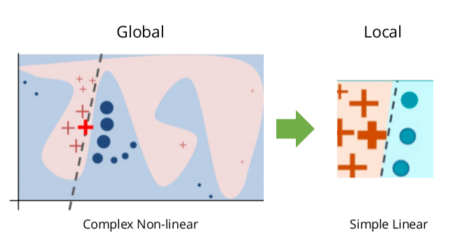
The idea was first given by Ribeiro et al. in 2016 in his paper “Why Should I trust You?”
The mathematical formula of LIME is:
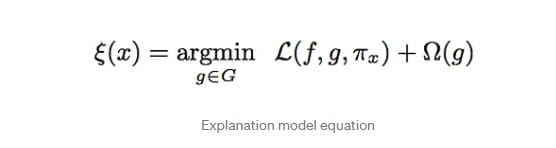
where,
x = point instance that we are interested in explaining
f = complex black box model
g = simple Interpretable model
G = Family of interpretable models
First term is a good approximation of complex model “f “by a simple interpretable model “g” in the neighbourhood of x denoted by Pi. It is also called the proximity.
Second term is omega, and it is used to regularize the complexity of interpretable model. This helps to get some zero-weighted features or lower depth decision trees and get only relevant features for explaining a particular point instance.
First, we generate the random datapoints in the neighbourhood of input data point (one for which we are seeking explanations) by altering the values of input variables. The data points which are nearer to the data point of interest gets more weightage. Then we generate the outcome of the newly generated datapoints from the complex model f which act as the ground truth and the outcome from simple models are predictions. The third step is to minimize the outcome of the complex model and simple model for these data points with a weight Pi giving more weightage to the instances closer to our data point of interest.
In short, this is an optimization problem where our objective is to find good approximation of our simple interpretable model “g” for a complex model “f” in the proximity of our data point x suggested by Pi and penalising the complexity of the model “g” (represented by omega) through lasso regression.
THE BUSINESS USE CASE
Let’s consider, the ask of the business is to predict loan default probability. This model needs to be very accurate as there is a risk of high defaults if the business is very lenient and starts giving loans to most applicants on the other hand there is an opportunity cost if the business is too strict with the loan applicants and the customers will be deterred to apply. So, simple explainable models like decision trees and logistic regression will not do justice. I have tried to use a more complex Gradient Boosting Machine (GBM) learning model to have more accuracy and explainability will be taken care of by LIME.
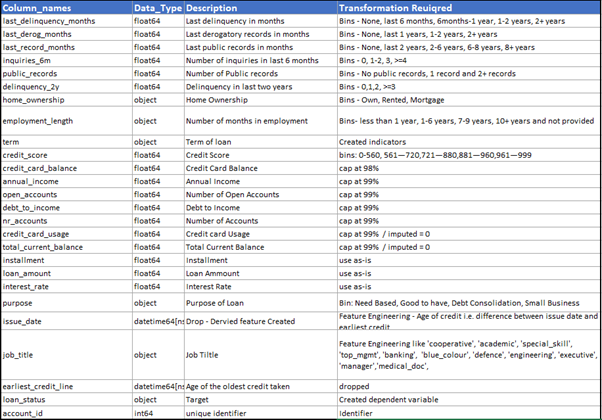
Below mentioned is the data dictionary along with the transformation done to the variables:
Let’s consider we already have a model in place called “lgb” which is being used here to get the predicted probability.
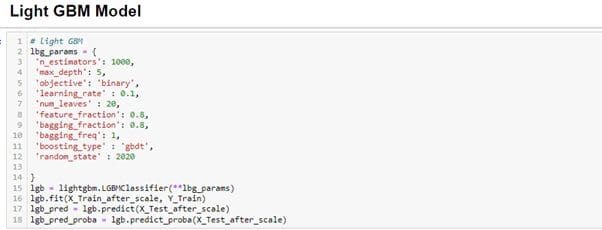


Code for getting the explanation of top 20 data points.

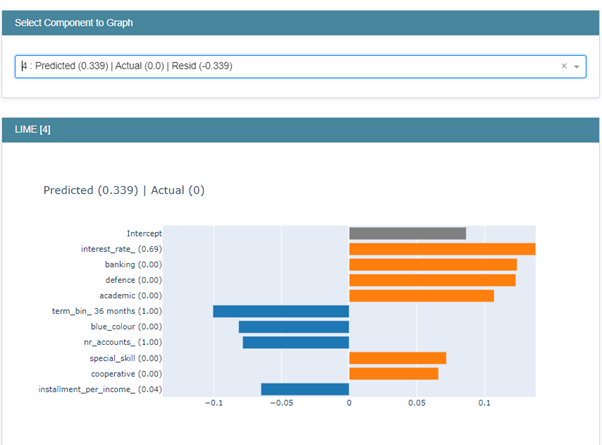
Here, Interest rate, indicator variables like “banking”, “defence”, “Academic”, “Special Skills” and “o-operative” are positively impacting the probability score. While “term_bin of 36 months”, “blue colour” indicator,“number of Accounts(nr_Accounts_)” and “installment as a percentage of income(Installment_per_income_) and negatively impacting the probability score.
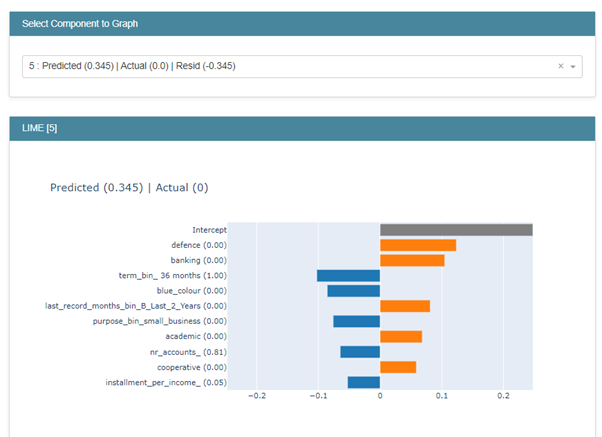
This case has different set of variables positively impacting the score and they are indicator variables like “defence”, “banking “academic” and “Cooperative” and numeric variable called” last_record_months_bin_last_2_years”. The blue coloured variables are negatively impacting the probability score.
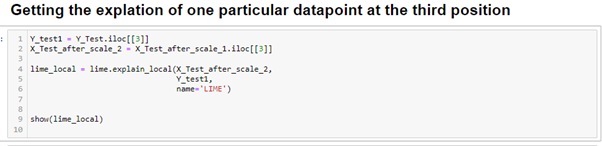
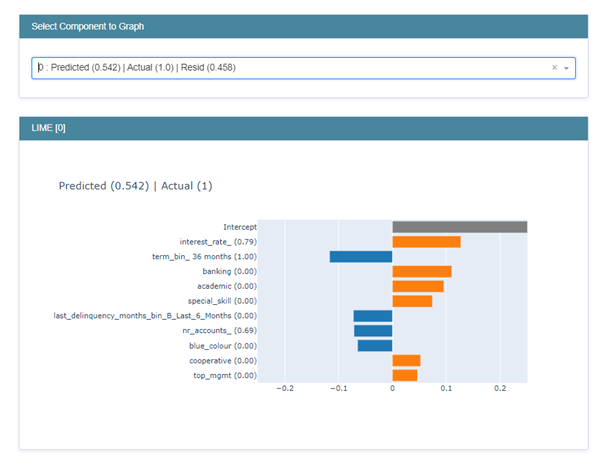
This case can also be explained similarly. The biggest contributor to the score is the interest rate and the variable which is negatively impacting the score is the term variable.
REFERENCE:
2. Explainable Al (XAI) with Python on Udemy.com by Prof. Prateek Bhatia
3. Decrypting your Machine Learning model using LIME | by Abhishek Sharma | Towards Data Science
4. LIME: Local Interpretable Model-Agnostic Explanations (c3.ai)

Abhigya Chetna is a data science professional. Over the years, she worked to provide analytical solutions in a wide range of industries across the globe. This diverse experience gives her an edge to crossbreed her skills and deliver impactful solutions.
She enjoys being an analytical translator for non-data professionals and aims to work for data literacy.







